En 2014 petit budget ne signifie pas nécessairement configuration bas de gamme et il est assez facile de faire tourner de grosses applications ou un grand nombre de sites internet pour quelques centaines, voire dizaines d’euros. En conséquence directe de la deuxième loi de Moore (qui annonce que la puissance des ordinateurs double tous les 2 ans) et de la guerre que se livrent les société d’hébergement, il est assez facile de se procurer 2 serveurs assez puissants pour bien moins cher qu’un seul serveur de la même puissance il y a 2 ans.
Cela explique que de plus en plus de société se tournent vers des configurations comportant plusieurs serveurs, avec une seule adresse présentée aux internautes. Ces configurations peuvent être plus ou moins complexes et dépendent à la fois des besoins et des ressources à allouer mais globalement ça ressemble à ça :
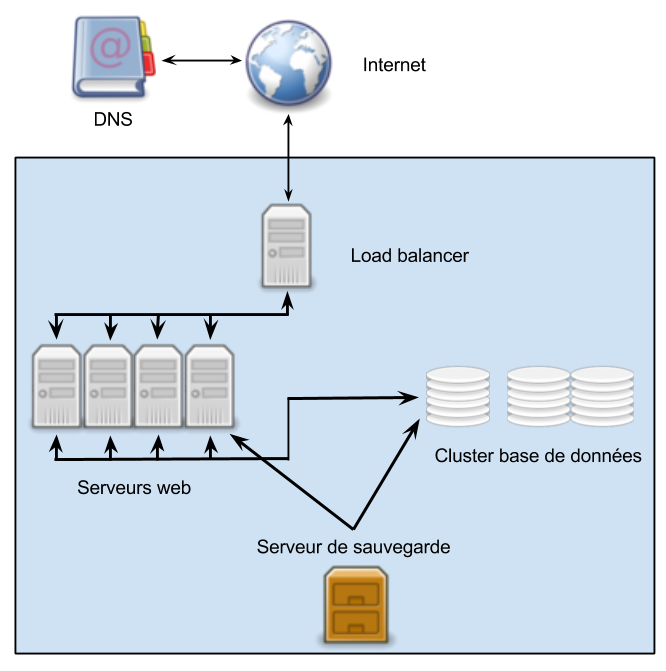
Un exemple de grappe de serveurs avec système de load balancing
De quoi se compose notre système ?
Je pense qu’il est nécessaire de détailler les éléments ci-dessus afin de comprendre leur rôle et la façon dont ils interagissent.
- Internet : il s’agit du client, l’internaute qui accède au site internet ou à l’application;
- DNS : lorsque le client veut accéder à une ressource sur internet, il fait appel à un serveur DNS pour faire la traduction entre le nom de domaine et l’adresse IP du serveur qui fournit la ressource. Ici le serveur DNS semble un peu hors sujet mais j’ai préféré l’inclure parce qu’il va jouer un rôle dans la mise en oeuvre que je vous proposerai par la suite;
- Load balancer : bien souvent il s’agit d’un serveur reverse proxy qui se charge de répartir les requêtes entre les différents serveurs de la grappe, parfois il s’agit d’une configuration plus complexe. Pour les montages simples, le load balancing est attribué au serveur DNS, nous y reviendrons par la suite. Ce que vous pouvez constater ici c’est que notre load balancer est le seul serveur visible depuis le monde extérieur.
- Serveurs web : nous avons ici une grappe de n serveurs (en fonction de la puissance demandée) dont le rôle est de traiter les requêtes et de renvoyer les ressources demandées. Les fichiers disponibles sur toutes ces machines sont strictement identiques. Bien souvent il s’agit même d’un cluster dans lequel tous les nœuds agissent comme une seule et même entité, parfois il s’agit de machines indépendantes qui ont un système de fichiers distribué tel que Glusterfs;
- Cluster base de données : les principaux systèmes de gestion de base de données sont capables de fonctionner en cluster, même sur des environnements hétérogènes. Pour cette raison, quelque soit le nombre de serveurs sur lesquels les bases de données sont réparties, j’ai choisi de les faire apparaître comme un cluster et non comme des serveurs distincts;
- Serveur de sauvegarde : il n’est peut-être pas nécessaire de s’étendre. Quel que soit le dispositif, il dispose d’une grande capacité de stockage et d’un accès à sens unique à l’un des serveurs applicatifs (s’ils ont tous les mêmes fichiers, inutile d’ouvrir une porte sur tous) et au cluster de base de données.
Les avantages et les inconvénients de cette solution
Les avantages de la solution
- Amélioration de la qualité et des temps de réponse des services : d’une manière générale travailler à 2 sur la même tâche permet d’aller plus vite que si l’on faisait le travail seul, et de moins se fatiguer. Pour un serveur c’est pareil : une machine sollicité à 90% en permanence sera moins efficace que 2 machines identiques sollicitées à 50%;
- Capacité à masquer la défaillance d’un ou de plusieurs serveurs : si le mécanisme de load balancing est bien configuré, il s’assurera qu’une machine est disponible avant de lui adresser une requête. Si un serveur tombe en panne, la seule chose que pourront constater vos internautes est une baisse des performances;
- Possibilité d’ajouter des machines sans interruption de service : il suffira d’intégrer un nouveau serveur à la grappe en dupliquant une configuration existante et de le déclarer au système de répartition de charge pour qu’il prenne sa place de façon totalement transparente;
- Sécurité des données : les bases de données ne sont pas disponibles sur les serveurs frontaux et elles ne sont pas accessibles à partir du “monde extérieur”. En toute logique il sera plus compliqué pour une personne mal intentionnée d’y accéder.
Les inconvénients de la solution
- Complexité de mise en oeuvre : mettre en place un serveur est une tâche qui en effraie plus d’un webmaster alors mettre en place une grappe de n serveurs + load balancer + serveur de backup demande réellement de l’expérience. De plus certaines formule d’hébergement ne vous proposeront pas les options nécessaires pour mettre en place telle ou telle fonctionnalité (liaison privée entre les serveurs, kvm pour installer une distribution personnalisée…);
- Coût d’exploitation : cette configuration demande au moins 6 serveurs actifs et est totalement injustifiée si on n’a que 2 serveurs d’application. Le coût augmentera mécaniquement avec le nombre de machines;
- Propagation des corruptions : Si chaque mise à jour d’un serveur est propagée aux autres machines, chaque problème est susceptible de l’être aussi. Ainsi si un fichier est effacé sur une machine (que ce soit par mégarde ou malveillance) il va certainement disparaître de toute la grappe, ce qui nous amène au point suivant : la sauvegarde.
Ce à quoi vous n’échapperez pas
Quoi qu’il arrive vous devrez toujours choisir une solution de sauvegarde parce que même si vos serveurs peuvent prendre le relais les uns des autres, il peut être nécessaire de retrouver ses fichiers tels qu’ils étaient il y a une semaine, un mois …
Vous devrez donc mettre en place un système de sauvegarde pour vos données, il s’agira d’une machine qui pourra lire vos serveurs mais qui refusera les connexions entrantes (à part celles venant de votre adresse IP) pour plus de sécurité.
Mettons en place une version simplifiée de ce système
Je vous propose de profiter des tarifs d’hébergement avantageux pour monter un système de deux serveurs web qui fonctionnent (quasiment) en miroir, avec un système de load balancing simple pour répartir aléatoirement les requêtes sur les 2 machines.
Notre configuration va être la suivante :
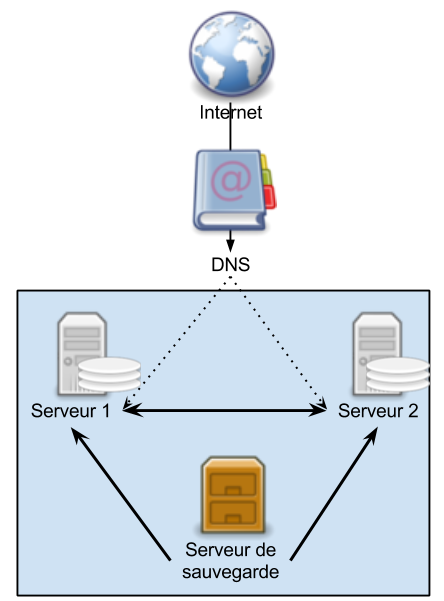
Exemple de configuration avec 2 serveurs en miroir et DNS Round Robin
- DNS : ici nous allons simplifier le mécanisme de load balancing en utilisant une répartition dite Round Robin qui peut s’apparenter aux portes tournantes d’un magasin : chaque requête passe à son tour. A moins de besoins spécifiques ça fonctionne très bien et ça a l’énorme avantage de ne pas faire travailler vos serveurs puisque la répartition des requêtes se fait avant d’atteindre vos machines;
- Serveurs web : pour économiser un peu d’argent nous allons héberger les sites / applications et les bases de données sur les mêmes machines. Nous sommes donc devant 2 problématiques :
- La synchronisation entre les fichiers : il n’est pas nécessaire de synchroniser les fichiers en temps réel, une simple mise a jour bidirectionnelle toutes les minutes fera l’affaire. Par contre nous ne pourrons pas synchroniser les dossiers de cache des sites puisque ce mode de réplication manque de réactivité et que maintenir ces répertoires à jour est plus coûteux en ressources que ça n’apporte de bénéfices. Cette synchronisation ne demande pas de système de stockage complexe et peut être faite avec un utilitaire très efficace appelé unison;
- Les bases de données doivent être répliquées en temps réel. Ce type de configuration est commun avec des serveurs Apache/MySql et il se trouve que MySql propose un système de réplicationmaître-esclave très efficace : les modifications effectuées sur le maître sont automatiquement recopiées sur l’esclave. Ceci est très bien dans le cadre d’un site éditorial sur lequel vous pouvez vous connecter au backoffice à partir d’une IP déterminée (le master en l’occurrence) et dont la base de données ne sera jamais modifiée en dehors de ces opérations. Par contre si vous ne maîtrisez pas à 100% le choix du serveur sur lequel les données seront écrites il va falloir mettre en place une réplication master-master, ce qui n’est pas beaucoup plus compliqué mais demande un peu plus d’efforts;
- Serveur de sauvegarde : nous allons louer un 3° serveur dans la même baie, un serveur de faible puissance avec une très grande capacité de stockage et des disques en RAID pour être certains de ne rien perde. Certains hebergeurs proposent des configurations spécifiques pour cet usage, leur pris est en général plus bas que celui de serveurs de production. La première chose à faire sur ce serveur est de couper l’accès au monde extérieur : vous seul pouvez avoir accès à cette machine, et elle ne peut se connecter qu’aux deux serveurs de production.
Est-ce réellement efficace ? je vous laisse juger : si les rapports qualité/prix des hébergements sont très variables, pour 250€ h.t. par mois, j’ai pu mettre en place cet automne une configuration de ce type capable de supporter environ 2.000.000 de visiteurs (pour 8.500.000 de pages vues) par mois… on est très loin des 200.000 visiteurs simultanés de certains géants de la vente éphémère, mais le coût de location est vraiment ridicule.
Vous avez pu découvrir le concept, je pense qu’il n’y a finalement pas de grosse difficulté dans la théorie. Mais la pratique peut se révéler plus compliquée. Dans les articles suivants nous allons donc découvrir ensemble :
- comment configurer 2 serveurs MySQL pour la réplication master-master : chaque mise à jour de données effectuée sur l’un des deux serveurs sera automatiquement répercutée sur l’autre ;
- comment synchroniser les fichiers de deux ordinateurs avec unison et crontab : les fichiers seront synchronisés dans les deux sens, en fonction de leur date de mise à jour ;
- un petit script pour sauvegarder automatiquement les fichiers et bases de données de vos serveurs : quelques lignes de code nous permettront de garder un historique de nos données sans avoir à y penser.
- et finalement comment mettre en place un firewall logiciel sur un serveur Linux avec iptables
En attendant de lire ces tutoriels, certains d’entre vous ont peut-être expérimenté d’autres configurations distribuées, ou totalement en cluster ? Ou peut-être que vous utilisez cette configuration et que vous souhaitez partager votre expérience à son sujet ? Comme toujours, les commentaires vous sont grand ouverts.